Note: Woven Planet became Woven by Toyota on April 1, 2023.

第6回AIエッジコンテスト表彰式(SIGNATE)
By Ryo Takahashi; Senior Engineer, Dennis Chen; AI Edge Engineer, Hiroyuki Aono; Embedded Machine Learning Engineer, Koichiro Yamaguchi; Staff Engineer and Ryohei Tokuda; AI Edge Engineer
Introduction
As we’ve recently announced, Woven Planet will shift to the next level to become Woven by Toyota in April. Data-driven software platforms will accelerate our development and delivery of safe mobility to the world, and enable us to reimagine the way we move and how we live.
We believe AI is key to increasing safety, fostering trust, amplifying human capabilities, and eventually delivering safe, intelligent, human-centered mobility to the world. With AI, we can help enhance the capabilities of drivers and empower people to thrive.
Arene, our software platform, aims to enable true state-of-the-art mobility programming as the basis for next-generation vehicles. With such innovative technology, we are all dedicated to realizing our vision of “Mobility to Love, Safety to Live” and providing mobility solutions that benefit all people worldwide.
What this contest is
This fiscal year, the five authors of this blog, who are developers of Arene, participated in a technical contest called the “The 6th AI Edge Contest (Implementation Contest 4)” for their skill development and won third place of the outstanding performance awards. This contest was held by METI (Ministry of Economy, Trade and Industry) of Japan, NEDO (New Energy and Industrial Technology Development Organization). The participants prototyped a 3D object detection system using RGB images and point cloud data from September 2022 to January 2023. While many machine learning (ML) contests are currently held around the world, this contest is unique in that it requires the use of RISC-V for some part of the inference process. As for the use of RISC-V, the participants were recommended to implement their own implementation on the Xilinx Kria™ KV260 FPGA board, rather than the off-the-shelf RISC-V boards available on the market. In brief, this contest is a technically interesting challenge that requires the participants to 1) train a ML model with the RGB images and point cloud data, 2) compile the model for the embedded board, 3) implement inference code such as pre- and post-processing, 4) implement a RISC-V processor on FPGA, and 5) build a baremetal system on RISC-V within five months.
Why we joined this contest
Why did we join a competition which involves FPGA implementation, despite being software engineers (SWE)? It is because hardware simulation techniques matter in automotive software testing. For example, when we release AD/ADAS (Automated Driving/Advanced driver-assistance system) software, we make a safety assessment after feeding very large testing data into our software as shown in Figure 1. At this point, it matters which hardware to use for testing. For AD/ADAS ECUs, we usually adopt energy-efficient edge processors (e.g. DSP, NPU), which are different from general-purpose processors for ML training. Naturally, from the perspective of safety assessment, it would be ideal to use the same edge processors as in the ECU. However, the scalability of the edge processors is very low before mass production, thus it’s not realistic to process all the testing data. On the other hand, we cannot naively use only general-purpose processors just for the sake of scalability. This is because general-purpose processors and edge processors usually differ at the ISA (Instruction Set Architecture) level. For example, when inference is performed using TensorFlow on NVIDIA GPUs, the inference results will differ from those from edge processors. A technique [1] has been proposed to reduce this difference as much as possible and reproduce inference similar to edge processors on GPU, but bit-level arithmetic accuracy cannot be guaranteed. Therefore, it’s hard to answer the question, “This mAP may be almost equivalent to GPU, but how does a few bits of different inference results in this scene affect our planner and controller?”. In several cases, with the help of a processor designer, we can use a tool to simulate edge processors on general-purpose processors. Nevertheless, even in this case, we cannot be satisfied in terms of speed because simulators such as ISS (Instruction-Set Simulator) and RTL (Register-Transfer Level) simulators become slower the more they focus on arithmetic accuracy. From this background, in order to pursue the safety of AD/ADAS, we need not only innovation in AI itself but also advance the Pareto front of scalability / arithmetic accuracy / speed. As an approach, we participated in this contest to familiarize ourselves with SWE-Friendly EDA such as Xilinx Vivado™/Vitis™ and HDL simulator acceleration technologies [2].
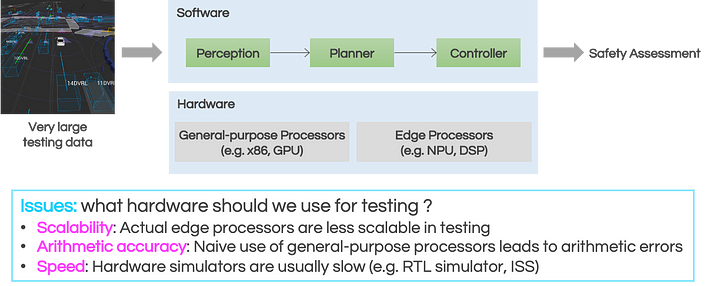
Figure 1: issues in automotive software testing
What model we trained/deployed
The recognition task in this contest is to detect objects of two classes, pedestrian and vehicle, in the form of 3D bounding boxes, using RGB images and point cloud data from driving vehicles.
RISC-V must then be used in part of this detection process, and when this condition is satisfied, the participants are evaluated from three perspectives, Inference Speed (ms), Accuracy (mAP), Engineering level (qualitative evaluation based on report). Under this regulation, we started development by exploring how much accuracy we can achieve using the point cloud data only. In this study, we assumed that the objects in this task don’t have a large variation in the Z-axis. Then, we chose PointPillars[3] as a base architecture, which encodes point cloud-based features into Bird-Eye View-based 2D features at a relatively early stage. We used MMDetection3D for training and achieved mAP=0.653. For model deployment to KV260, we used the Post-Training Quantization feature in Vitis AI. After confirming that the mAP didn’t drop severely (mAP=0.648), we reported this result as our final accuracy.
How we ran PointPillars
To run the above model on the KV260, we used Vitis to design the hardware architecture shown in Figure 2. In this architecture, DPU, a proprietary systric array from AMD (Advanced Micro Devices, Inc.), and VexRiscv, an open-sourced RISC-V, are placed in the PL (Programmable Logic) area of KV260. We load the bitstream and device tree through ZYNQ™ UltraScale+™’s Dynamic Function eXchange (DFX) feature so that our Linux application can use those IPs from Arm® Cortex®-A53 in the PS (Processing System) area. Specifically, we use Vitis AI Runtime for DPU. As for VexRiscv, although naïve, we offload a computation task by storing its bare-metal ELFs into BRAM (a kind of SRAM in PL) then resetting the RISC-V core via GPIO every invocation.
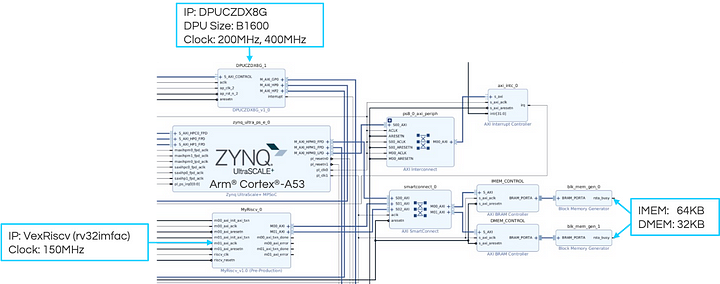
Figure 2: Vivado block design of our hardware architecture
The software architecture of our inference application is as shown in Figure 3. We divided PointPillars into five modules from the Preprocess to the Postprocess from our implementation perspective. The algorithm names such as Voxelization and HardVFE in each module correspond to classes in the training framework, MMDetection3D. For the Preprocess, we compiled the PyTorch C++ Extension for aarch64 to save implementation time and easy consistency assurance. For the neural network part, our strategy was to utilize the DPU as much as possible using Vitis AI. However, the intermediate process, equivalent to GatherND in ONNX, could not be compiled in Vitis AI 2.5, so we adopted CPU fallback. The Middleprocess was also implemented using PyTorch for aarch64. On the other hand, since we were planning to offload the Postprocess to RISC-V, we implemented the get_bboxes of CenterPoint [4] in full-scratch C. Due to a toolchain issue, we couldn’t run the entire PostProcess on RISC-V, but RISC-V was used within this module. Sequential execution of these five modules resulted in an inference time of 714 ms per run (bittersweet result for this contest..).
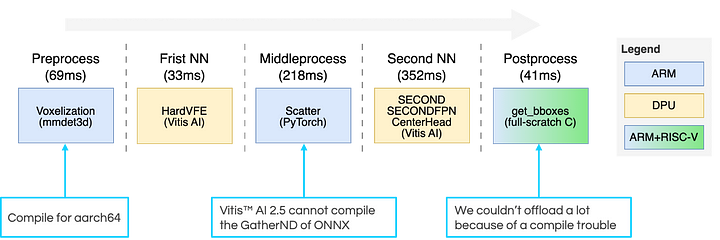
Figure 3: software architecture of our inference application
Future works
Now that several ISO 26262 ASIL-ready RISC-C cores emerge, we believe that RISC-V will be used for automotive software in future. Towards such an era, we will not only address the above toolchain issue but also get deep dive into optimization work of core frequency, gate counts, ISA, and so on. In the area of hardware simulation, our real interest is not in accelerating FPGAs and simulators themselves, but in improving the total throughput. Therefore, in the near future, we will need to bring the efforts in the hardware simulation area into our Kubernetes-based testbed. If you have a passion for or excitement about our strategies like above, leave a response in this blog!
Reference
Benoit Jacob, Skirmantas Kligys, Bo Chen, Menglong Zhu, Matthew Tang, Andrew Howard, Hartwig Adam, Dmitry Kalenichenko. Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 2704–2713, 2018
Wilson Snyder. Verilator, Accelerated: Accelerating development, and case study of accelerating performance. 2nd Workshop Open-Soure Design Automation (OSDA), 2020
Alex H. Lang, Sourabh Vora, Holger Caesar, Lubing Zhou, Jiong Yang, Oscar Beijbom. PointPillars: Fast Encoders for Object Detection from Point Clouds. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 12697–12705, 2019
Tianwei Yin, Xingyi Zhou, Philipp Krähenbühl. Center-based 3D Object Detection and Tracking. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 11784–11793, 2021