Note: Woven Planet became Woven by Toyota on April 1, 2023.

By Stefano Pini, Research Scientist, Eesha Kumar, Software Engineer, and Christian Perone, Staff Machine Learning Research Engineer
This December, Woven Planet will once again be participating at the NeurIPS Workshop on Machine Learning for Autonomous Driving (ML4AD)! The Conference on Neural Information Processing Systems (NeurIPS) is a top international venue for research in machine learning, and is now in its 36th year. The ML4AD workshop, in its 7th year, aims to promote discussions between different ML subfields towards the common goal of achieving automated driving, and is widely attended by both industry and academia.This year we will be presenting two pieces of work from our London-based Fleet Learning team at Woven Planet. Both relate to the problem of machine learning for Autonomous Vehicle (AV) planning: given an AV which can localize itself in and perceive the world around it, how can it learn to most safely and efficiently get from A to B? We will present two improvements to machine learning solutions for this key challenge on the road to delivering automated driving.
Part I. A Mixture of Experts model for capturing multi-modal driving behaviours.
Consider driving along a street with a small obstacle in your path. To get around the obstacle, do you drive to the left of it, or to the right? Previous approaches to machine learned planners for AVs would output a single solution, which in the worst case could lead to averaging both the left and right options and driving down the middle, into the obstacle (an obvious flaw!).In this work, we develop a model which allows an AV to maintain a set of viable solutions. At run-time, multiple solutions are predicted and the AV can select the one which best meets various criteria, such as safety and comfort. To accomplish this, our model also predicts possible future actions of other road agents, such as vehicles and pedestrians. Since our model learns by watching human drivers, it can improve with training data and is simple to implement.We tested our model both in simulation and driving on busy, urban roads around our office in Palo Alto. As shown in the video above, we found that it can drive safely without compromising comfort.For further details, please see our project page.
Part II. A new approach to Empirical Risk Minimization.
A common technique used today for teaching an AV to drive is known as “behavioural cloning”, in which the AV learns to mimic the observed behaviours of human drivers as seen in recorded data logs. One of the main issues with using behavioural cloning in practice is the mismatch between training and inference-time distributions. At train-time, policies are learned by finding the mapping between observed past and future behaviours that exist in the recorded data logs. This is known as “open-loop”, since the observed environment is played back from the logs, and does not respond to the learned policy. At inference-time, the problem becomes “closed-loop”: the observed environment does respond to the policy’s actions. This can lead to cascading errors, if the policy’s actions push the AV into state spaces which have not been visited during training. Although precautions can be taken to reduce the likelihood of cascading errors, a model which performs better during open-loop training does not necessarily perform better under closed-loop evaluation.
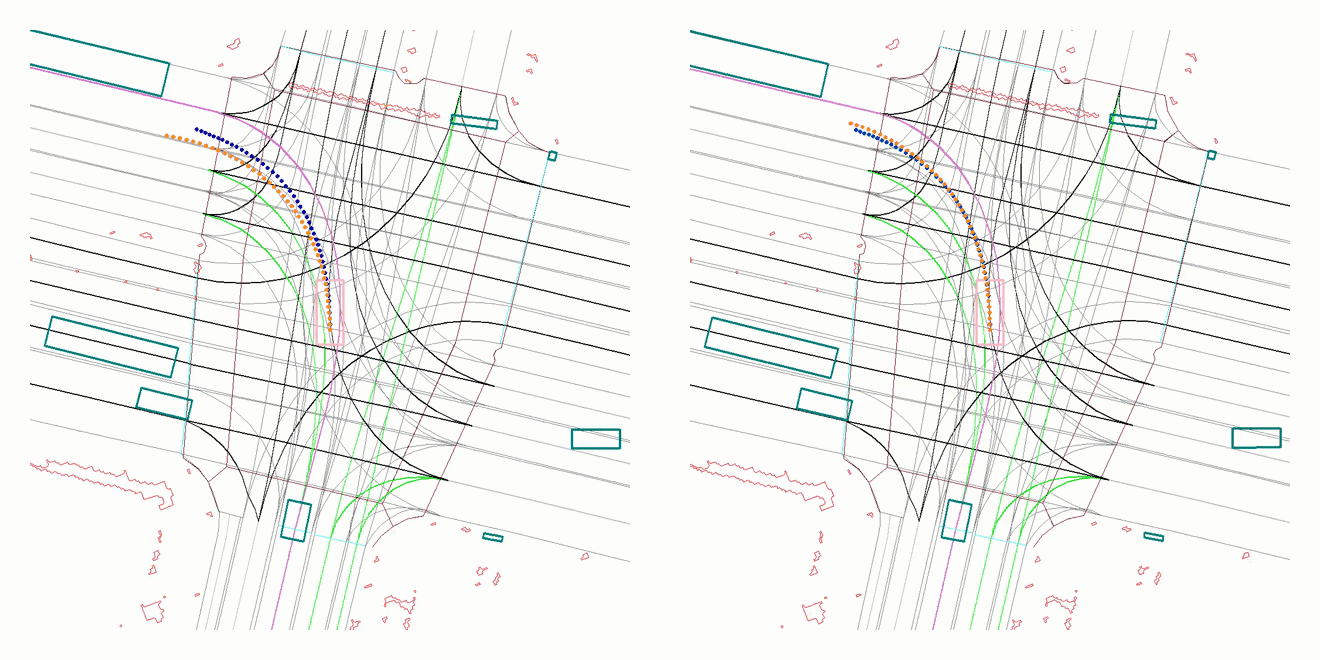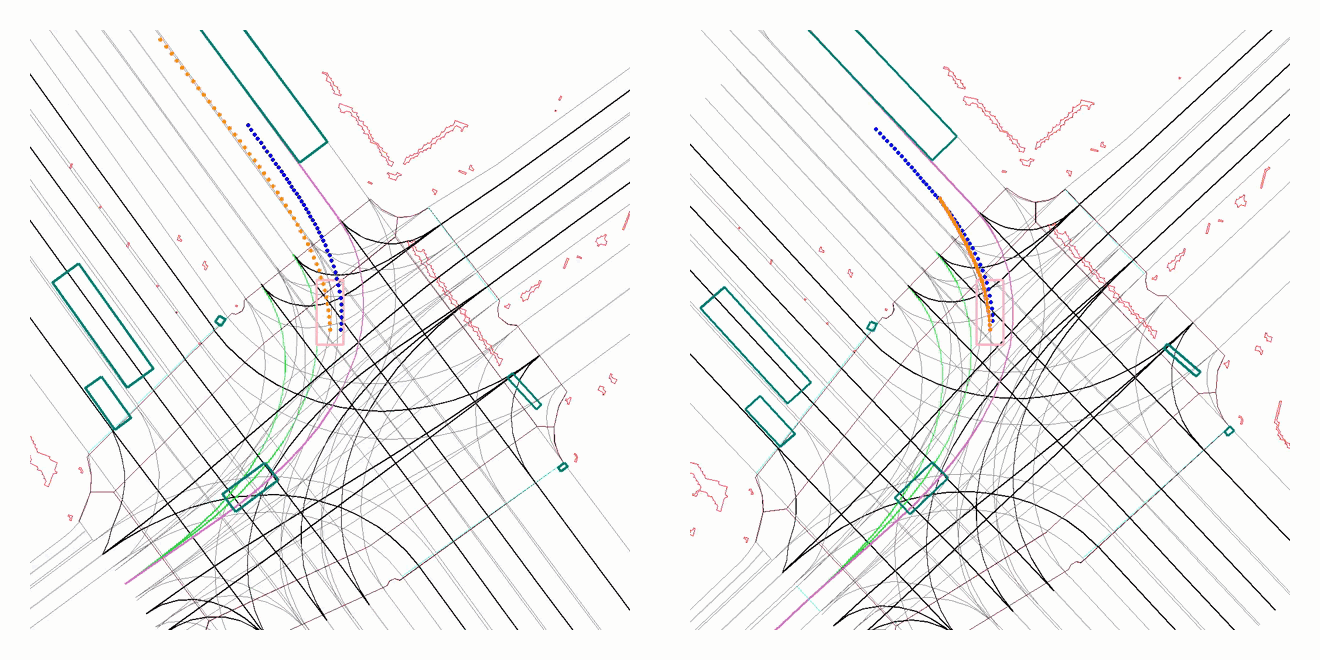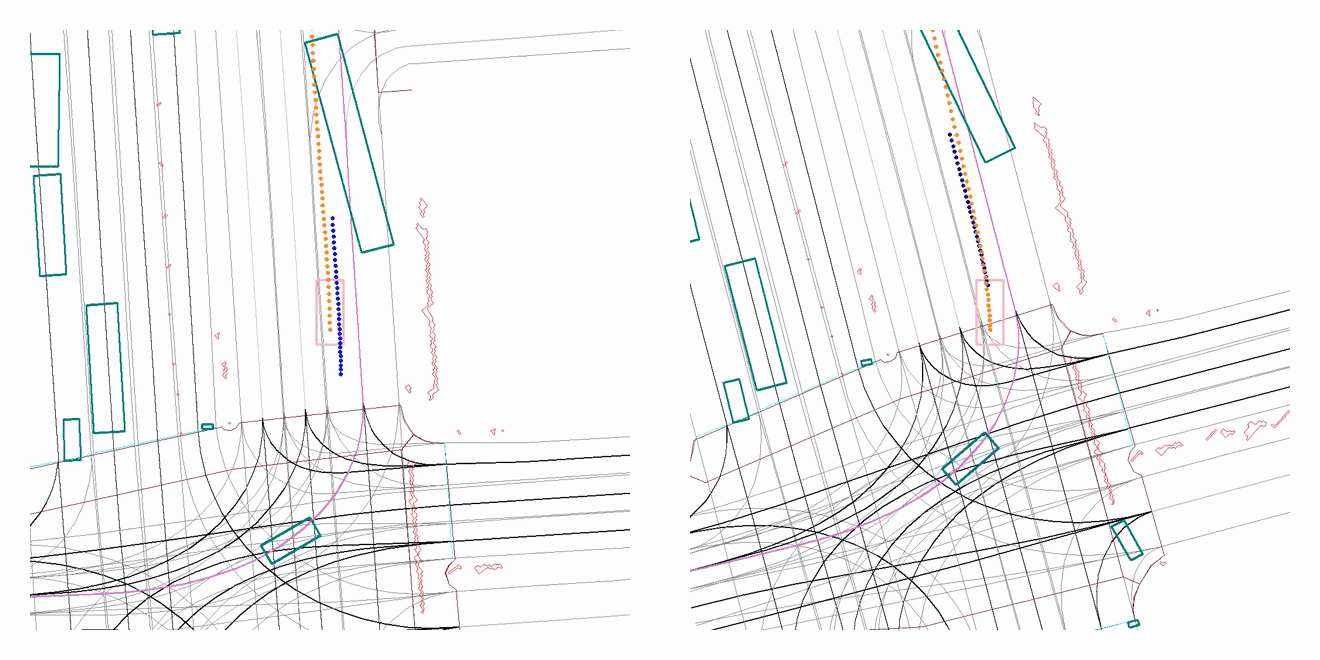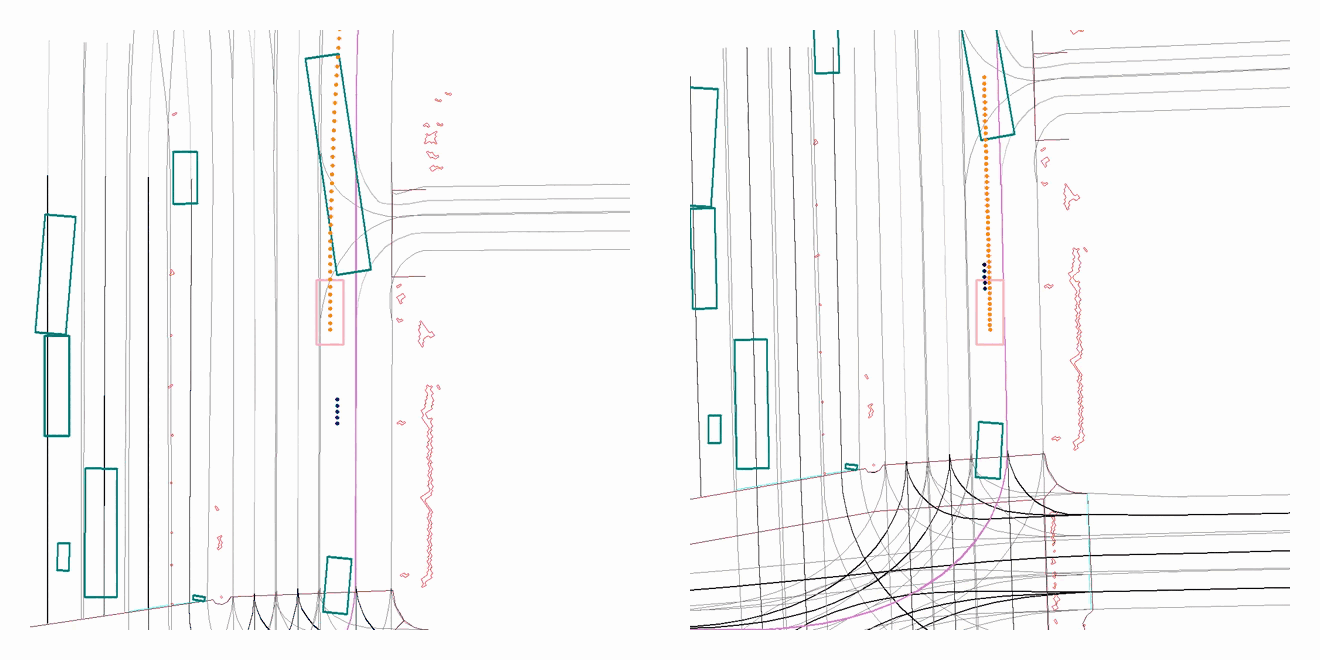
A driving sample from our evaluation set, showing the improved behaviour of the AV after training with our proposed approach. The (old) policy on the left causes a front collision as the long vehicle suddenly pulls out in front of it, while the (new) policy on the right learns how to yield correctly for traffic ahead.
To counteract this, we developed a training principle that can help to reduce the bias of the distribution of data samples seen by the model during training in such a way that the gap between open-loop training and closed-loop testing performance is narrowed. We evaluated our scheme, called CW-ERM (Closed-loop Weighted Empirical Risk Minimization), experimentally on a challenging real-world urban driving dataset. We showed that it yields significant improvements in closed-loop performance without requiring complex and computationally expensive closed-loop training methods.For further details, please see our project page.
Come join us! 👋
If you’re interested in helping to solve important problems at the intersection of machine learning and AVs, please check out our jobs board for positions in the UK, US, and Japan!