Note: Woven Planet became Woven by Toyota on April 1, 2023.

By Takuya Ikeda (Senior Engineer), Suomi Tanishige (Engineer), Ayako Amma (Senior Engineer), Michael Sudano (Senior Engineer), Hervé Audren (Senior Engineer), Yuki Igarashi (Senior Engineer), and Koichi Nishiwaki (Principal Robotics Researcher), in the Robotics Team of the Woven City Management Team
Introduction
Hitting some important milestones including a groundbreaking ceremony and a safety prayer ceremony, some of you may have heard of Woven City that is being built in Susono, Shizuoka, Japan, as a big and bold project led by Toyota Motor Corporation together with Woven Planet Holdings, Inc. (Woven Planet). Woven City is a test course for mobility to realize our dream of creating well-being for all. We aim to conduct trials of new ideas for systems and services that expand mobility and unlock human potential.
As robotics engineers, from the perspective of the everyday mobility of goods, we aim to help Woven City’s residents save time to enjoy their lives by giving them options such as providing them with a tidying-up service. To realize such services, we believe the robotics that can acquire, sort, manipulate, and use household objects could be of assistance, and object pose estimation in indoor scenes is one such core technology, as shown in Fig.1.

[Fig.1]
Challenging Problems
Recently, Deep Neural Networks (DNNs) show many great results for object pose estimation. However, one big difficulty is the 6D pose (rotation + translation) labeling. The reason why is that DNNs commonly need a large amount of data with precise labels. Also, it is a quite difficult task to do precise 6D pose labeling manually on many images as shown in Fig.2.
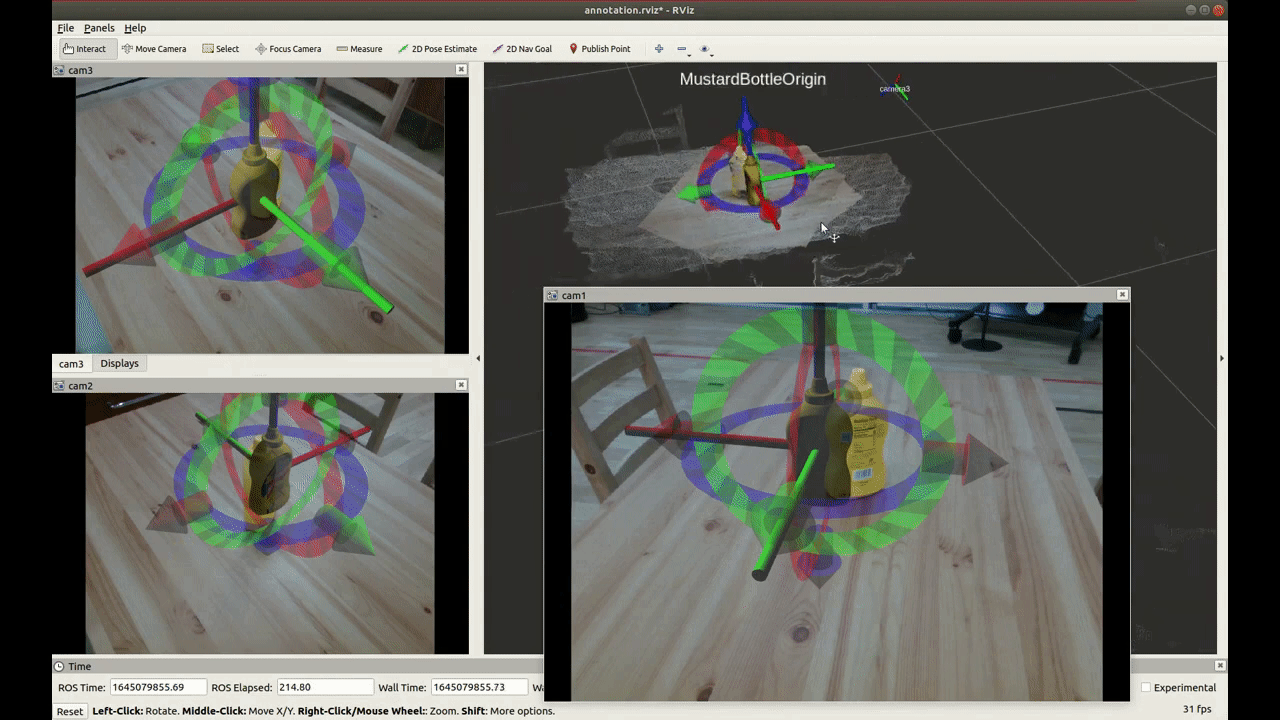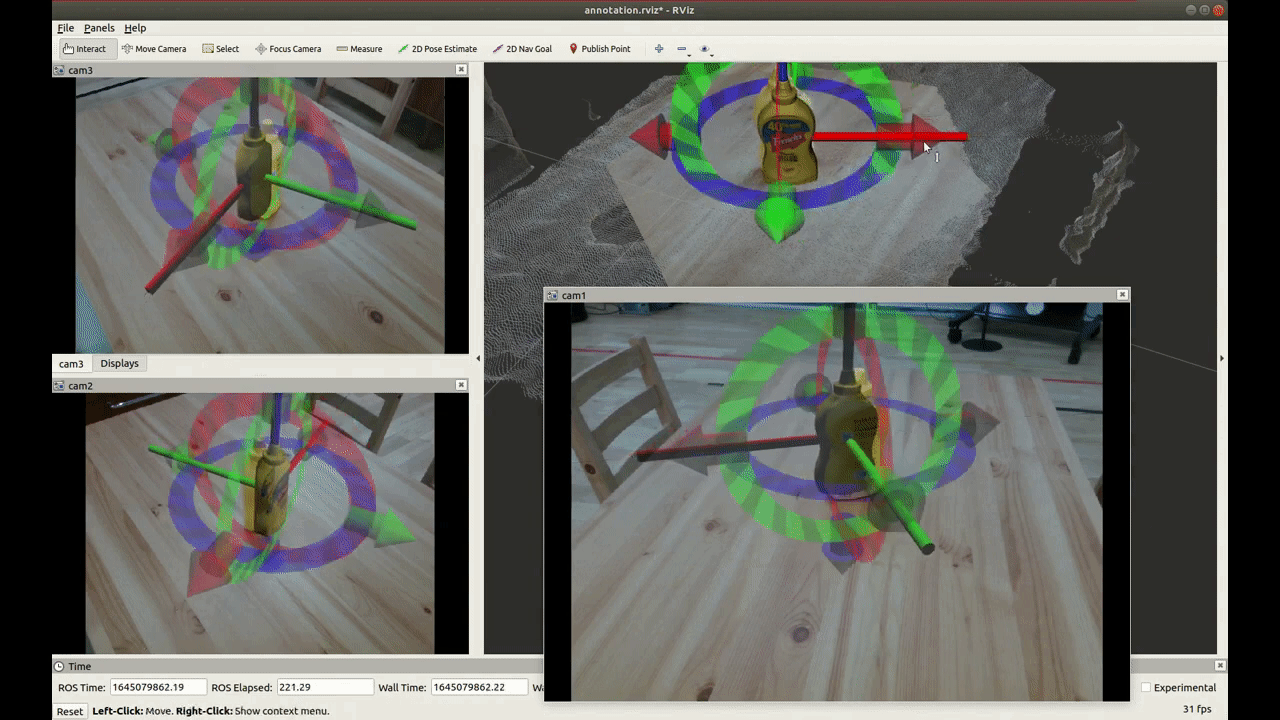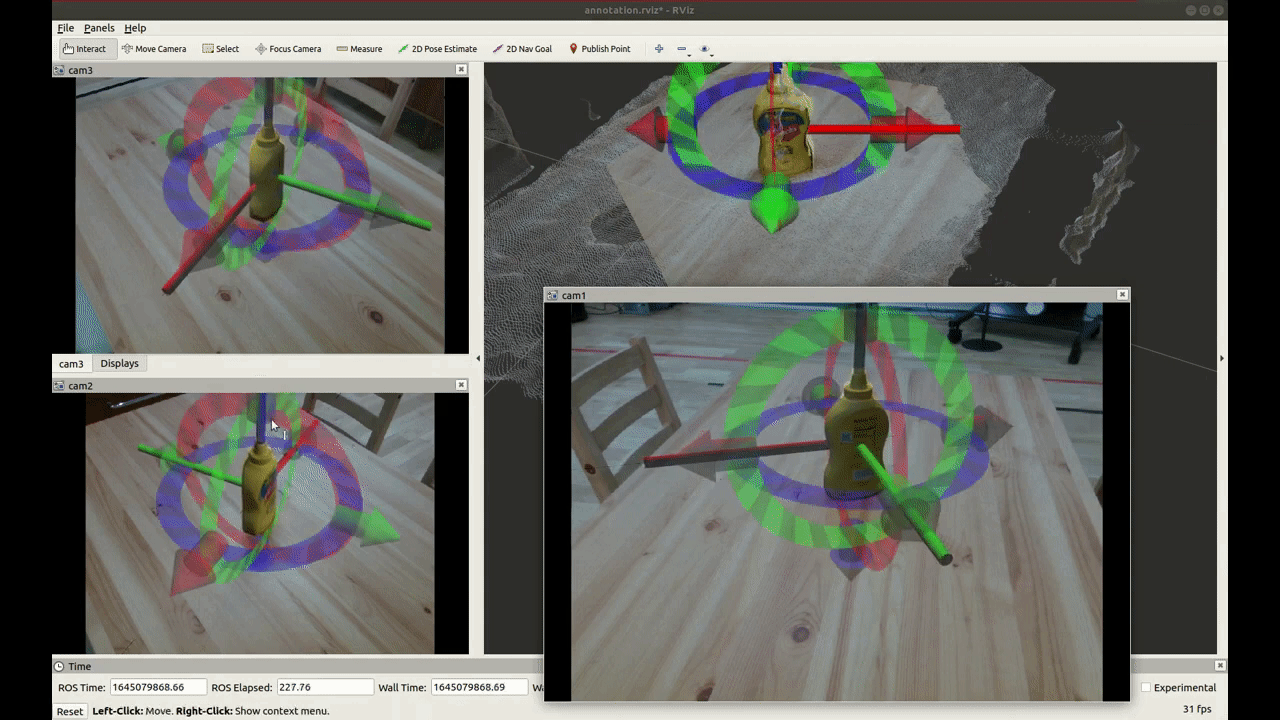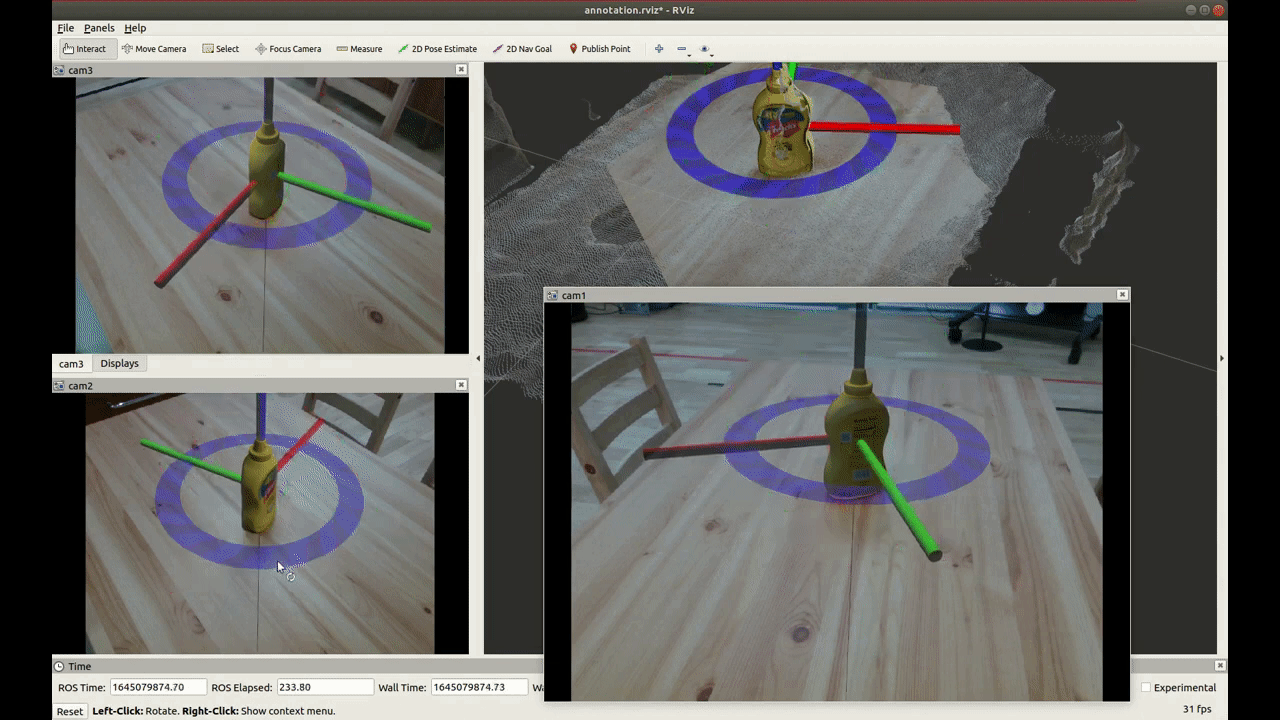
[Fig.2]
Use of Simulation
One promising solution is the use of simulation to generate synthetic data since any number of perfectly annotated images can be generated. Much research shows positive results using only synthetic data for 6D pose estimation network training [1].
Moreover, simulation has a large variety of benefits. For example, it not only allows us to do rapid prototyping of robotics applications but also provides an automatic way of testing the applications (e.g. automatic nightly regression testing on continuous integration) as shown in Fig.3.

[Fig.3]
However, there is one difficult problem, especially for perception developments, which is the fidelity gap. Although the renderer’s quality is improving day by day, it is still difficult to make complex material, like transparency and specularity, realistic in the simulation with low-cost as shown in Fig.4. It usually takes an amount of time to adjust the lighting and material to be realistic by comparing with the human eye.

[Fig.4]
How to bridge the fidelity gap between simulation and reality?
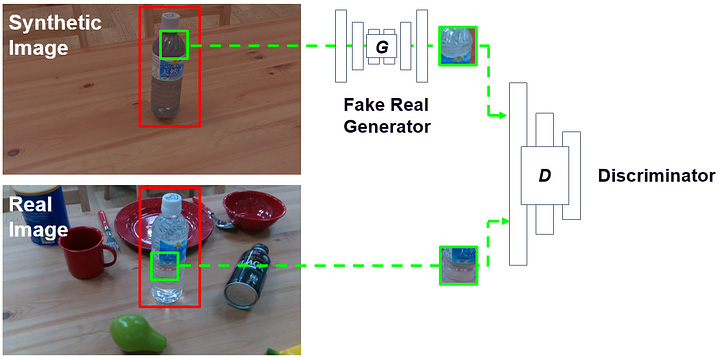
Our suggestion is to improve 6D pose estimation network performance via sim2real object style transfer [2]. In other words, we bridge the fidelity gap between simulation and reality without manual annotation by using unsupervised style transfer. Fig.5 is an overview of our sim2real domain adaptation method.
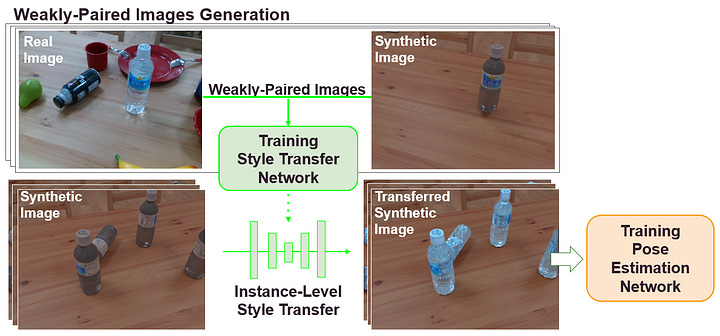
[Fig.5]
First, we gather real data using a robot and render target objects using given 3D models and poses which are estimated from a pre-trained network using only synthetic data. Then, the style transfer network is trained in an unsupervised manner using these images that we call “Weakly-Paired Images” as shown in Fig.6.
[Fig.6]
After the training, the network is able to transfer target object areas in synthetic images to be more realistic ones as shown in Fig.7.
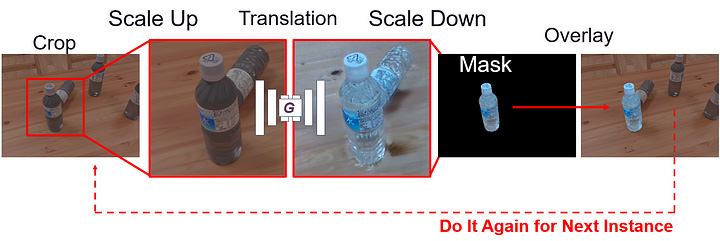
[Fig.7]
Lastly, the pose estimation network is trained using the transferred images, instead of raw-synthetic data.
For transfer network training, we collect and use minimal real data, under the assumption that less data is required for a style transfer network than for a pose estimation network. Once the style transfer network is trained, it may be used to generate any number of realistic images from synthetic data for the training of the 6D pose estimation network. Since we don’t do any manual data gathering and annotations, the time and cost of them can be saved.
Evaluation of the performance
For quantitative evaluation for 6D pose estimation accuracy, we use the popular ADD metric (average model distance, in meters). Fig.8 is the result of a pose estimation network that is trained using non-style-transferred and style-transferred images.
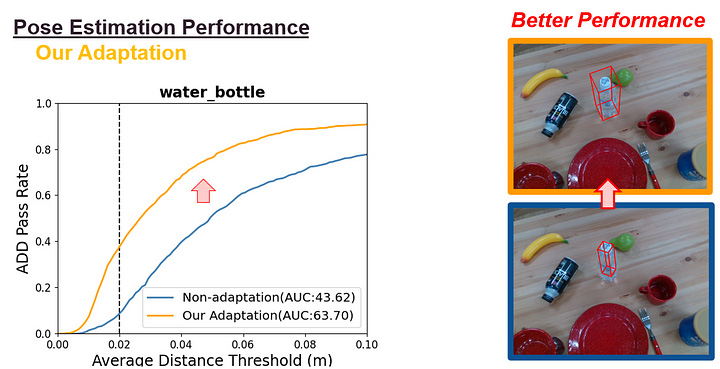
[Fig.8]
Qualitatively, our approach is able to stably transfer all target objects as shown in Fig.9; competing methods (CycleGAN [3], DRIT [4], CUT [5]) contain shape collapse, style mismatches, and visible artifacts around objects.

[Fig.9]
Discussion
As can be seen in the top row of Fig.10, the original synthetic image doesn’t contain specularity, but after translation, it better resembles the real image which contains realistic reflection. One final interesting result to note as can be seen in the bottom row: the object labels on the real object (all blue) and 3D model (contains a section of red) are different, presumably due to a product update after the item was scanned. Remarkably, our approach is able to bridge the label color difference gap.


[Fig. 10]
Conclusion
We introduced an unsupervised sim2real style transfer method for 6D pose estimation. As a result of being able to successfully bridge transparency, specularity, and texture mismatch gaps, we believe that our method will enable the wider application of sim2real techniques.

Study Presentation
This study was presented at the IROS 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems, one of the world’s largest robotics research conferences held in Kyoto on October 23–27, 2022.
If you would like to see what the event looked like, please visit our Woven City website event report page!
Join us! 👋
We are actively hiring exceptional talent for the robotics team. If you are interested in working with us in our office in Nihonbashi, Tokyo, please have a look at our current open positions!
Reference
Tremblay, Jonathan, Thang To, Balakumar Sundaralingam, Yu Xiang, Dieter Fox, and Stan Birchfield. “Deep object pose estimation for semantic robotic grasping of household objects.” arXiv preprint arXiv:1809.10790 (2018).
Ikeda, Takuya, Suomi Tanishige, Ayako Amma, Michael Sudano, Hervé Audren, and Koichi Nishiwaki. “Sim2Real Instance-Level Style Transfer for 6D Pose Estimation.” arXiv preprint arXiv:2203.02069 (2022).
Zhu, Jun-Yan, Taesung Park, Phillip Isola, and Alexei A. Efros. “Unpaired image-to-image translation using cycle-consistent adversarial networks.” In Proceedings of the IEEE international conference on computer vision, pp. 2223–2232. 2017.
Lee, Hsin-Ying, Hung-Yu Tseng, Jia-Bin Huang, Maneesh Singh, and Ming-Hsuan Yang. “Diverse image-to-image translation via disentangled representations.” In Proceedings of the European conference on computer vision (ECCV) , pp. 35–51. 2018.
Park, Taesung, Alexei A. Efros, Richard Zhang, and Jun-Yan Zhu. “Contrastive learning for unpaired image-to-image translation.” In European conference on computer vision
, pp. 319–345. Springer, Cham, 2020.