Prediction Dataset
Prediction Dataset
The largest collection of traffic agent motion data
This dataset includes the logs of movement of cars, cyclists, pedestrians, and other traffic agents encountered by our automated fleet. These logs come from processing raw lidar, camera, and radar data through our team’s perception systems and are ideal for training motion prediction models. The dataset includes:



EXPLORE
Prediction dataset sample
The dataset consists of 170,000 scenes capturing the environment around the automated vehicle. Each scene encodes the state of the vehicle’s surroundings at a given point in time.
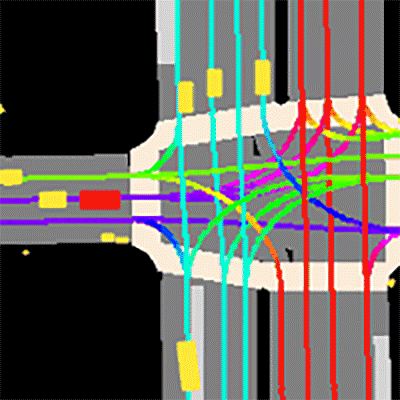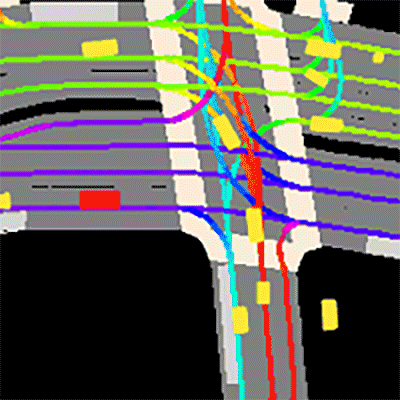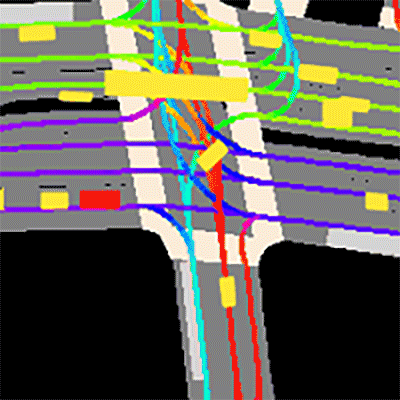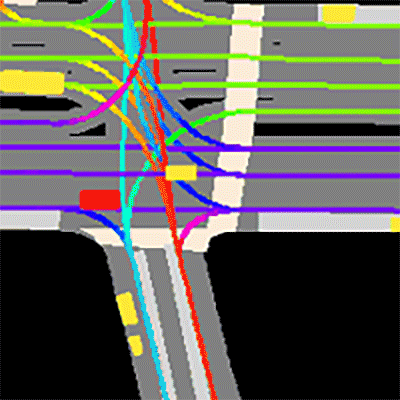

GET STARTED
Example prediction solution
This baseline solution is trained on over 2 million samples from the agent locations contained within the dataset. The model predicts a single agent at a time. First, the model generates a bird’s eye view (BEV) top-down raster, which encodes all agents and the map. The network infers the future coordinates of the agent-based upon this raster.

DATA FORMAT
The dataset is provided in zarr format. The zarr files are flat, compact, and highly performant for loading. To read the dataset please use our Python software kit. The dataset consists of frames and agent states. A frame is a snapshot in time which consists of ego pose, time, and multiple agent states. Each agent state describes the position, orientation, bounds, and type.
FRAME_DTYPE = [
(“timestamp”, np.int64), // Time the frame occurred.
(“agent_index_interval”, np.int64, (2,)), // Agents contained within the scene.
(“ego_translation”, np.float32, (3,)), // Position of ego vehicle, used for image generation and pose transformations.
(“ego_rotation”, np.float32, (3, 3)), // Rotation of ego vehicle, used for image generation and pose transformations.
]
AGENT_DTYPE = [
(“centroid”, np.float32, (2,)), // Center of the agent.
(“extent”, np.float32, (3,)), // Size of agent.
(“yaw”, np.float32), // Agent heading.
(“velocity”, np.float32, (2,)), // Agent velocity (relative to heading, x is forward, y is left)
(“track_id”, np.int32), // Unique identifier for agent
(“label_probabilities”, np.float32, (len(LABELS),)), // Probability of the agent being a car, truck, pedestrian, etc.
]
Download the prediction dataset kit
DOWNLOAD
1. The following subsets are available:
2. Download Our Python Software Kit
We created this kit to read the data. Use the software code documentation for more information on the kit.
3. Download the Example Motion Prediction Solution for Reference
Our example solution will give you a starting point for experimentation.
CITATION INSTRUCTION
If you use the dataset for scientific work, please cite the following:
@misc{Woven Planet Holdings, Inc. 2020,
title = {One Thousand and One Hours: Self-driving Motion Prediction Dataset},
author = {Houston, J. and Zuidhof, G. and Bergamini, L. and Ye, Y. and Jain, A. and Omari, S. and Iglovikov, V. and Ondruska, P.},
year = {2020},
howpublished = {\url{https://woven.toyota/en/prediction-dataset}}
}
LICENSING INFORMATION
The downloadable “Woven by Toyota Prediction Dataset” and included semantic map data are ©2020 Woven Planet Holdings, Inc. 2020, and licensed under version 4.0 of the Creative Commons Attribution-NonCommercial-ShareAlike license (CC-BY-NC-SA-4.0).
The HD map included with the dataset was developed using data from the OpenStreetMap database which is ©OpenStreetMap contributors will be released under the Open Database License (ODbL) v1.0 license.
The Python software kit developed by Woven by Toyota to read the dataset is available under the Apache license version 2.0.
The geo-tiff files included in the dataset were developed by ©2020 Nearmap Us, Inc. and are available under version 4.0 of the Creative Commons Attribution-NonCommercial-ShareAlike license (CC-BY-NC-SA-4.0).