Note: Woven Planet became Woven by Toyota on April 1, 2023.
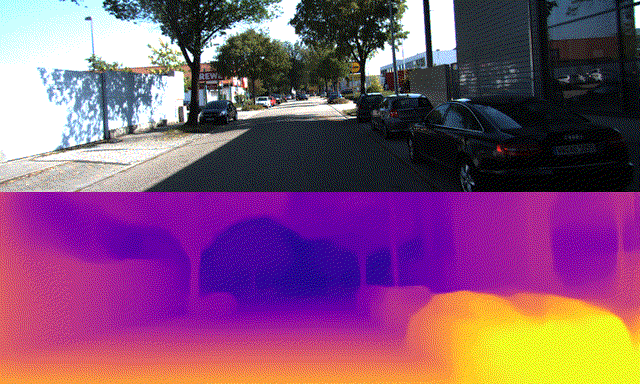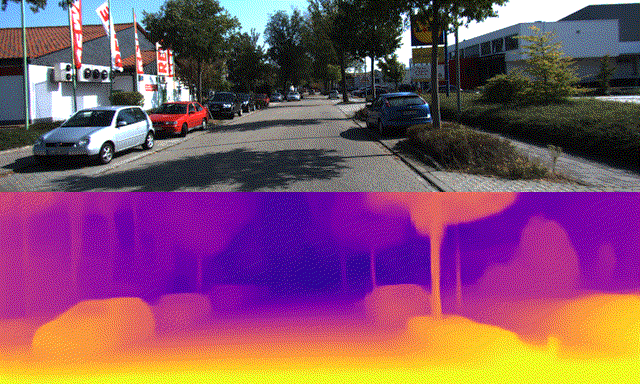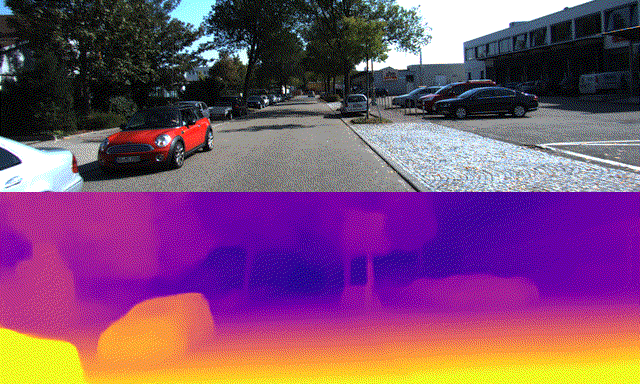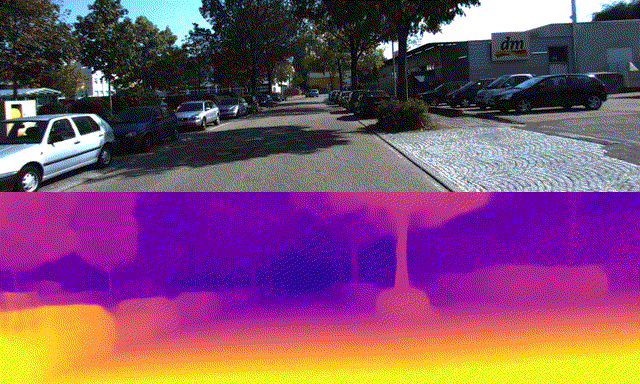
By Yuki Kawana, Koichiro Yamaguchi, Takaaki Tagawa and Yusuke Yachide, Engineer, Staff Engineer, Senior Engineer and Senior Manager
Arene aims to enable true state-of-the-art mobility programming as the basis for next-generation vehicles. With such innovative technology, we are all dedicated to bringing our vision of “Mobility to Love, Safety to Live” to life, and providing mobility solutions that benefit all people worldwide. In order to accelerate the development of machine learning (ML) models suitable for deployment in vehicles, the Arene AI team at Woven Alpha, Inc. (Woven Alpha), an operating company of Woven Planet Holdings, Inc. (Woven Planet), has been developing a neural architecture search (NAS) framework that automatically searches for neural network (NN) architectures that meet the computational resource constraints of the target hardware. In this article, we will present the results of our study on NAS for the monocular depth estimation task targeting in-vehicle computing environments.
Woven Planet is making a company-wide effort to build a fast automated driving software development process that will allow us to update our in-vehicle systems multiple times a day. In order to achieve such a fast development cycle, it is essential to actively automate the development process. In today’s automated driving systems, ML models using NN play an important role in recognition systems. In the development process of the recognition system, the design of the NN architecture requires not only high recognition performance but also computational performance that satisfies the severe computational resource constraints of the in-vehicle computing environment. On the other hand, there is generally a trade-off between recognition performance and computational performance, and designing a NN architecture that satisfies both requirements requires a great deal of time and effort, as it is usually done manually through repeated experiments. In addition, since the required computational performance can change not only due to the constraints of the target vehicle’s computational environment but also due to changes in the required specifications, the design of an in-vehicle NN architecture requires even more time and cost. Therefore, we believe that it is important to have a method to develop the optimal NN architecture at high speed by automatically searching for the NN architectures that satisfy the requirements of both recognition performance and computational performance.
NAS is a method to automatically search the suitable NN architectures for the given task. Arene AI has been developing the NAS framework for detection and semantic segmentation tasks, which are essential in recognition systems. In addition to the previously mentioned tasks, the next generation of automated driving systems are expected to utilize NN models to perform the task of estimating high-resolution depth maps from RGB images, i.e., monocular depth estimation, to estimate the distance to the vehicle ahead and to understand the shape of objects on the road. In the latest training of NN models for monocular depth estimation, self-supervised learning has been proposed, which learns highly accurate NN models for monocular depth estimation from a large number of images by training using only videos, even when there is no available ground-truth depth map as supervision signal. In some cases, the ground-truth depth map can be obtained from LiDAR data in the road scenes, but in general, videos obtained from RGB cameras have higher resolution with the larger amount. Therefore, it is desirable to use self-supervised learning from video sequences. However, in previous studies, when NAS is used to explore the NN architecture for the monocular depth estimation task, they assume that the ground-truth depth map is available at the time of architecture search [1, 9].
In this study, we investigate the NAS approach for the monocular depth estimation task without using the ground-truth depth map. We assume that there already exists a NN model for the monocular depth estimation task that has been trained by self-supervised learning, which performs well but does not satisfy the computational performance of the in-vehicle computing environment. Then, we investigate the NAS approach using knowledge distillation (KD) method to find a NN architecture with better computational performance; we use the depth map predicted by the trained model as a pseudo ground-truth, instead of using the ground-truth depth map. We choose KD over self-supervised learning during the architecture search for faster and more stable convergence of the training process of the candidate architectures. There are previous studies that use KD to learn depth estimation models with specific NN architectures [6, 8] and use NAS for image classification and detection tasks [5, 7]. In contrast, the main purpose of this study is to confirm that KD is effective not only in training the specific NN architectures, but also in exploring the NN architecture, especially for the monocular depth estimation task.
Using the KITTI dataset [2] and the DDAD dataset [3], we confirmed that the NN architecture found by this method has outperforming depth estimation and computational performance (lower latency in the target in-vehicle computational environment) than the ResNet18-based model used as a baseline from [3], and is compatible with the state-of-the-art model, PackNet [3].
Problem setting
In road scenes, the ground-truth depth map is not always available. The previous research [1, 9] performed NAS using a synthetic dataset with computer graphics. NAS is performed using the dataset with the ground-truth depth map, then the found architecture is re-trained on the real dataset. However, if the domain gap between the target dataset and the synthetic dataset is large, the found architecture is not necessarily optimal.
Therefore, in this study, we consider a method to perform NAS on the target dataset without using the ground-truth depth map. In this study, we employ KD using the estimated depth map by the NN model for the monocular depth estimation task, which has been trained by self-supervised learning, using a pseudo ground-truth depth map. This makes it possible to use NAS without using the ground-truth depth map. In this study, we also assume that the trained model performs well but does not meet the in-vehicle computational performance requirements. In terms of computational performance, it is essential to consider not only the low latency of the inference, but also using only arithmetic operations that are supported on the target computing environment. Given the estimated depth of this trained model on the target dataset as a pseudo ground-truth depth map, our goal is to search for a NN architecture that has higher computational performance with as close depth estimation performance as possible to that of the trained model, and uses only arithmetic operations supported by the target computational environment.
Method
In KD, a trained model is called a teacher model, and a model that is trained by the output of a teacher model is called a student model. In this study, we use PackNet [3] as a teacher model. PackNet has state-of-the-art self-supervised depth estimation accuracy, but is computationally expensive and not deployable to the in-vehicle computing environment due to some layers not supported by the target hardware. As a deployable baseline, we use the model that has an encoder using ResNet18 and a lightweight depth map decoder from [3]. This model is also used as the baseline in [3]. In this study, we use NAS to search for an encoder architecture which we have found computational bottleneck of the baseline architecture. Our goal is to find a NN architecture that is computationally efficient while maintaining the same level of depth estimation performance as the teacher model. The architecture of the decoder is the same as the baseline. As the loss functions for the architecture search, we use the mean squared error between the estimated depth maps of the teacher model and the student model, and the latency-aware loss proposed in [4] to consider the computational performance during the architecture search. The entire pipeline is shown in the figure below.
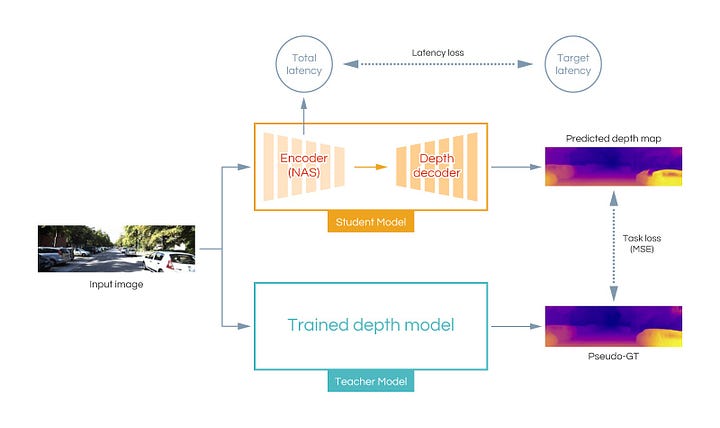
The candidates of network layers explored by NAS are limited to ones using arithmetic operations supported by the target hardware, focusing on two-dimensional convolutional layers with various kernel sizes.
Experiments
In this study, we constrain the architecture search through the latency loss considering the in-vehicle computing environment. We evaluate our approach on the KITTI dataset [2] and on a more challenging dataset, the DDAD dataset [3].
The results of the quantitative evaluation are shown below.

The first row in the table shows the evaluation metrics, and the subsequent rows show the evaluation results of each model. The first column represents the methods to be compared, and the second to eighth columns are depth estimation accuracies evaluated with various commonly used metrics. Upwards / downwards arrow indicates a higher / lower number is better. Bold fonts mean the best value within the same metric. The last column shows the average inference latency per image on the target computing environment. The latency of PackNet is n/a (not available) because it cannot be run on the target computing environment due to unsupported layers on the target computing environment.
Our approach outperforms the baseline ResNet18 model in depth estimation performance with 58% less latency. Thus, we can see that our approach finds a superior encoder architecture than the manually designed ResNet18 architecture. A comparison with PackNet also shows that it achieves comparable depth estimation performance: PackNet performs specialized computations such as 3D convolution and pixel shuffle [10], to prevent information loss by the spatial resolution reduction in the encoder. On the other hand, our approach achieves the comparable depth estimation performance using only standard 2D convolution and pooling layers, which are supported in the standard in-vehicle computing environment.
The results of further comparison using the DDAD data set are shown below.

In comparison to the baseline ResNet18 model, our approach outperforms depth estimation accuracy with 64% less latency. In the DDAD dataset, PackNet outperforms our model in majority of the metrics, however, our approach performs more similarly to PackNet than the baseline ResNet18 model.
Conclusion
In this article, we have presented the study on NAS using KD for the monocular depth estimation task. The found architecture is about 60% faster than the manually designed ResNet18-based baseline model, and also achieves superior depth estimation accuracy. In addition, we have shown that it achieves the comparable or closer depth estimation accuracy to PackNet than the baseline ResNet18 model. Through this study, we have confirmed that KD performs well in NAS application to monocular depth estimation task to find NN architectures suitable for in-vehicle computing environments even when the ground-truth depth map is not available. The current main limitation of our approach is that the depth estimation accuracy is upper-bounded by the teacher model. However, previous studies suggest that a NN architecture that outperforms the teacher model can be found using NAS with KD in a trade-off with computational performance. Future investigation will explore the pareto optimal trade-off between computational performance and depth estimation accuracy, and also the application of NAS with KD for other tasks. We continue to work on the ML technology to improve the fast development cycle in Woven Planet.
We thank you for reading the contents of this page. Now we are seeking new members who can join us. If you are interested in contributing to Arene AI team, please apply for the open posts here!
Reference
Xuelian Cheng, Yiran Zhong, Mehrtash Harandi, Yuchao Dai, Xiaojun Chang, Hongdong Li, Tom Drummond, and Zongyuan Ge. Hierarchical neural architecture search for deep stereo matching. Advances in Neural Information Processing Systems, 33, 2020.
Andreas Geiger, Philip Lenz, and Raquel Urtasun. Are we ready for autonomous driving? the kitti vision benchmark suite. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 3354–3361, 2012.
Vitor Guizilini, Rares Ambrus, Sudeep Pillai, Allan Raventos, and Adrien Gaidon. 3d packing for self-supervised monocular depth estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 2485–2494, 2020.
Yibo Hu, Xiang Wu, and Ran He. Tf-nas: Rethinking three search freedoms of latency-constrained differentiable neural architecture search. In Proceedings of the European Conference on Computer Vision, pp. 123–139, 2020.
Changlin Li, Jiefeng Peng, Liuchun Yuan, Guangrun Wang, Xiaodan Liang, Liang Lin, and Xi-aojun Chang. Block-wisely supervised neural architecture search with knowledge distillation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp.1989–1998, 2020.
Yifan Liu, Changyong Shu, Jingdong Wang, and Chunhua Shen. Structured knowledge distillation for dense prediction. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020.
Bert Moons, Parham Noorzad, Andrii Skliar, Giovanni Mariani, Dushyant Mehta, Chris Lott, and Tijmen Blankevoort. Distilling optimal neural networks: Rapid search in diverse spaces. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 12229–12238, 2021.
Andrea Pilzer, Stephane Lathuiliere, Nicu Sebe, and Elisa Ricci. Refine and distill: Exploiting cycle-inconsistency and knowledge distillation for unsupervised monocular depth estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 9768–9777, 2019.
Tonmoy Saikia, Yassine Marrakchi, Arber Zela, Frank Hutter, and Thomas Brox. Autodispnet: Improving disparity estimation with automl. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 1812–1823, 2019.
Wenzhe Shi, Jose Caballero, Ferenc Huszar, Johannes Totz, Andrew P Aitken, Rob Bishop, Daniel Rueckert, and Zehan Wang. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 1874–1883, 2016.