An introduction and tutorial for training machine learning motion prediction models using Woven Planet’s Prediction Dataset
Note: Woven Planet became Woven by Toyota on April 1, 2023. Note: This blog was originally published on September 24, 2020 by Level 5, which is now part of Woven Planet. This post was updated on December 13, 2022.
By Luca Bergamini, Software Engineer; Vladimir Iglovikov, Software Engineer; Filip Hlasek, Engineering Manager; and Peter Ondruska, Head of Research
Predicting the behavior of traffic agents around an autonomous vehicle (AV) is one of the key unsolved challenges in reaching full self-driving autonomy. With our Prediction Dataset and L5Kit, you can start building motion prediction models in a free afternoon or weekend — even if you have no prior AV experience.
What is motion prediction and why is it important?
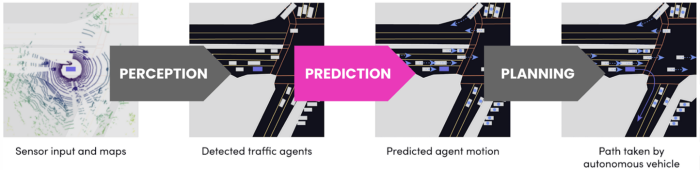
Three main components of AV stack: Perception (What is around the car?), Prediction (What will happen next?), Planning (What should the car do?).
Let’s start with how the self-driving car works. Within the AV stack, the first step toward building a self-driving system is perception (identifying what’s around us). The next two tasks are prediction (determining what will happen next) and planning (deciding what the AV is going to do in the future). We’re focusing on this second task.
AVs need to be able to make predictions about the future — something drivers do subconsciously all the time. Imagine an AV trying to turn left while another car is approaching from the opposite direction. In order for the AV to perform this maneuver safely, it needs to determine whether the other car will turn right or continue driving straight and interfere with the left turn. This is exactly what motion prediction is about.
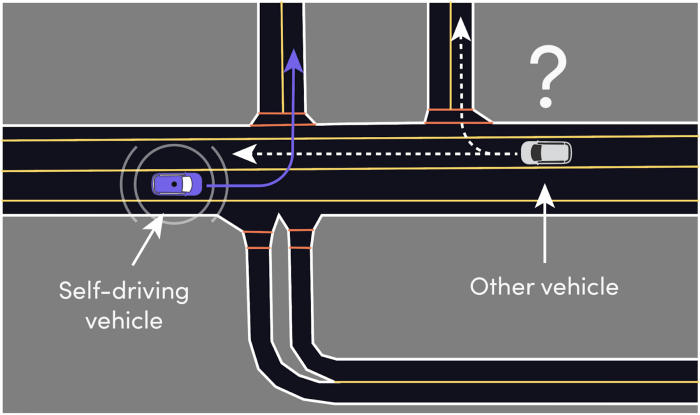
Example situation: for the self-driving car to perform an unprotected left turn, it needs to know whether the oncoming vehicle will turn right or go straight and interfere with the AV’s left turn.
While perception is considered production-ready within the industry, prediction and planning still need improvement. Why are these later parts of the AV stack still unsolved for AVs?
Today, models for motion prediction and planning are mainly built using rule-based systems. However, the future is uncertain and rules may not always scale well with uncertainty. As you add other agents into the mix, the number of rules and costs grow exponentially. A deep supervised learning approach could address that, but you need a lot of data to properly capture rare and unexpected behaviors of the road. Good news: our Prediction Dataset is the largest of its kind and includes these rare behaviors.
Training your model
To train your model, you need to:
Download the Prediction Dataset
Get input and output for the Task
Define the Model
Train the Model
We prepared a Jupyter notebook to make these steps simple.
1. Download the Prediction Dataset
Visit our Prediction Dataset webpage to register and download the dataset. This dataset includes more than 1,000 hours of driving data over 16,000 miles collected by our fleet of AVs in Palo Alto, California. We’ve already run the dataset through our internal production perception stack since building prediction models is hard to do efficiently when starting with raw data. This means you can immediately get started building motion prediction models for traffic agents already identified in our perception outputs, and measure your progress against our ground truth.
In addition to the data, we’ve also included an aerial map and high-definition semantic map annotated by our researchers. You can read about it more here.
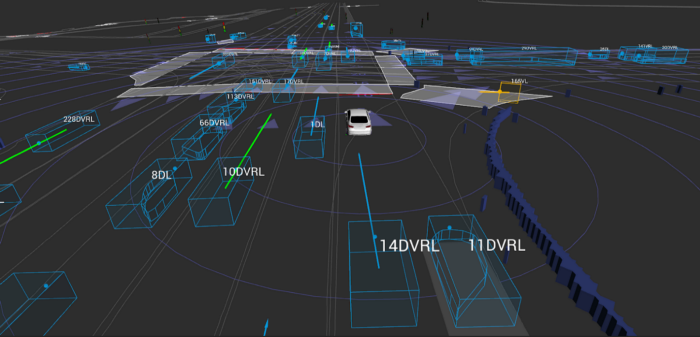
Snapshot of the Prediction Dataset, which contains 1,000 hours of driving collected by our AV fleet in Palo Alto, CA.
2. Getting input and output for the task
The Prediction Dataset registers the world around the AV at different timestamps. Each timestamp includes:
A frame
A frame is a record of the AV itself. It contains its location and rotation, as well as a list of all the agents and traffic lights detected around it in that instant.
Agents
An agent is a movable entity in the world. Agents are labeled with a class (car, pedestrian, etc.) and position information. Agents also have unique IDs, which are tracked between consecutive frames.
Getting information for frames and agents is as simple as running this snippet of code:
zarr_dt = ChunkedDataset("PATH")
zarr_dt.open()
for frame in zarr_dt.frames:
print(frame["ego_translation"], frame["ego_rotation"])
for agent in zarr_dt.agents:
print(agent["centroid"], agent["yaw"])
example_frames_agents.py hosted with ❤ by GitHub
A common choice when working with AV data is to use Bird’s-Eye View (BEV) rasterization for the system’s input, which consists of top-down views of a scene. This simplifies building your models because the coordinate spaces of the input and output are the same.
Getting BEVs and output trajectories ready for training a DCNN is a matter or few lines:
cfg = load_config_data("CONFIG PATH")
rast = build_rasterizer(cfg, LocalDataManager("DATASET PATH"))
dataset = AgentDataset(cfg, zarr_dt, rast)
agent_idxs = range(0, len(dataset))
for agent_idx in tqdm(agent_idxs):
data = dataset[agent_idx]
img = data["image"] # BEV input
translations = data["target_positions"] # future translations for the agent
example_bev.py hosted with ❤ by GitHub
Input BEVs overlaid on our HD semantic maps looks like this:

Examples of driving scenes from the dataset capturing position of other agents around the AV.
3. Define the model
Define a model to train using your inputs and outputs. You can create a simple baseline by adapting a standard CNN architecture (e.g. ResNet50) to your needs. While you can leave the central part of the network as-is, you’ll need to change its input and output layers to match your setting.
To do this, match the number of channels in the first convolutional layer to the one in the BEV. A 3-channel convolutional layer is not enough to rasterize different semantic information in different layers. Next, make sure the number of outputs matches your future prediction horizon multiplied by each timestep element (XY displacements are used in the example below). For a horizon of 50 steps, you’ll need a total of 100 neurons in the last layer of our network.
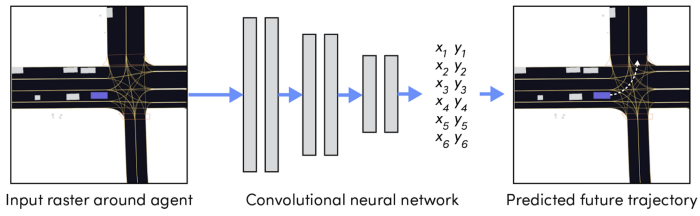
A simple neural network accepting bird’s-eye-view raster around the agent and predicting its future trajectory.
In PyTorch this looks like:
model = resnet50(pretrained=True)
# change input channels number to match the rasterizer's output
model.conv1 = nn.Conv2d(
num_in_channels,
model.conv1.out_channels,
kernel_size=model.conv1.kernel_size,
stride=model.conv1.stride,
padding=model.conv1.padding,
bias=False,
)
# change output size to (X, Y) * number of future states
model.fc = nn.Linear(in_features=2048, out_features=num_targets)
example_model.py hosted with ❤ by GitHub
4. Train the model
You’re now ready to train the baseline model on the data. The model will be fed with BEV inputs and asked to predict future trajectories. You can set up a Mean Squared Error (MSE) criterion and optimize the network using the ADAM optimizer. In PyTorch this looks like:
optimizer = optim.Adam(model.parameters(), lr=1e-3)
criterion = nn.MSELoss(reduction="none")
outputs = model(torch.from_numpy(img)).reshape(translations.shape)
loss = criterion(outputs, translations)
optimizer.zero_grad()
loss.backward()
optimizer.step()
example_train.py hosted with ❤ by GitHub
We can also plot the predicted trajectories on BEV rasters centered around the AV after a few iterations.
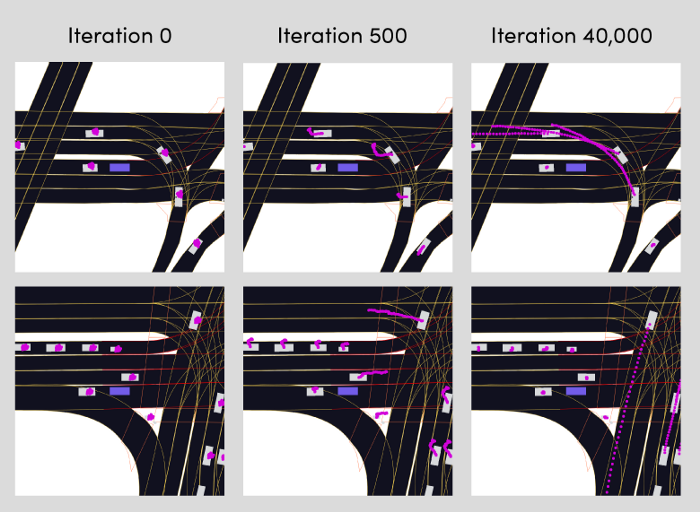
Progress of training the motion prediction model over time.
Take your model a step further
Here are some ideas and tips to improve and experiment with your model:
Simply replace the first and last layer if you’re striving for speed and want to replace ResNet with the lighter EfficientNet.
Want to see if an agents’ history can improve performance? That’s just a matter of changing a configuration value and everything works out-of-the-box.
You can increase the raster’s resolution and even change its aspect ratio if it looks too coarse.
Is one trajectory per agent not enough to capture the uncertainty? We already provide metrics to score multi-modal predictions, so you can know straight away if your model improves.
Join us!
We’re looking for talented engineers to help us on this journey. If you’d like to join us, we’re hiring!